以长三角某智算中心为例 揭秘多智算中心一体化运营运维与结算体系
随着人工智能产业的爆发式增长,多地、多中心的智能计算中心(智算中心)已成为支撑区域乃至国家算力网络的关键基础设施。其高效、稳定、经济的运营运维(O&M)与精准的设备结算体系,是实现算力资源高效调度与商业价值最大化的核心。本文将以长三角地区某大型运营商主导的“一核多翼”智算中心集群为例,系统阐述其运营运维与结算体系的构建与实践。
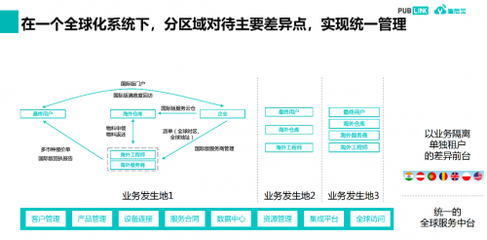
一、 案例背景:一体化“算力网”的构建
该案例中的智算中心集群,以位于上海的核心枢纽数据中心为“核心”,在杭州、南京、苏州等地建设了多个具有差异化算力配置(如侧重AI训练、推理或科学计算)的边缘智算节点为“多翼”。目标是通过统一平台,实现跨地域算力资源的整合、弹性调度与一体化服务。
二、 核心挑战与运营运维架构
面对地理分散、技术栈复杂、需求多样等挑战,该集群构建了“集中管控+属地执行”的混合运营运维模式。
- 集中运营中心(COC):设立于上海核心枢纽,承担“大脑”职能。
- 统一监控:通过自研的运维管理平台,对全部中心的IT设备(GPU服务器、存储、网络)、动力环境(电力、制冷)进行7x24小时实时全景监控。
- 资源调度与编排:根据客户作业需求、各中心资源利用率、网络延迟和电价等因素,通过智能算法实现算力任务的跨中心最优部署。
- 标准化流程制定:建立统一的设备上架、巡检、变更、故障处理(SOP)和应急预案。
- 属地运维团队:各智算中心驻地配备专职技术团队,负责:
- 现场物理操作:硬件巡检、设备上下架、线缆维护、本地故障初步排查与硬件更换。
- 执行标准化流程:严格遵循COC下发的工单和指令进行现场操作。
- 协同支持:与当地电力、网络供应商对接,保障基础设施稳定。
- 智能化运维(AIOps)应用:平台利用AI进行故障预测(如通过GPU运行日志预测显存故障)、能耗优化(动态调整制冷策略)和容量规划,变被动响应为主动预防。
三、 关键环节:精细化设备结算体系
清晰的结算体系是商业运营的基石,尤其涉及高价值的GPU等算力设备。该案例采用“资源度量 + 服务分级 + 动态计价”的模型。
- 结算对象与度量维度:
- 算力资源:以“GPU卡时”或“算力单元(如FP16 TFLOPS-小时)”为核心度量单位,精确记录客户占用的各类GPU(如A100、H800)的计算时长。
- 存储资源:按高速SSD存储的容量(GB)和I/O吞吐量分级计费。
- 网络资源:跨中心数据迁移流量、对外带宽单独计量。
- 软件与服务:预置的AI框架、模型库及专业调优服务按许可或服务包形式结算。
- 结算流程与平台:
- 统一账户与计量:客户拥有唯一账户,可在平台上跨中心申请和使用资源。底层计量系统自动采集所有资源消耗数据,汇聚至结算中心。
- 账单生成:根据预设的价目表(单价可能因数据中心区位、采购成本、实时负载产生浮动),按日或按周生成明细账单,清晰展示各中心、各项目的消耗量与费用。
- 差异化定价策略:
- 地域差价:考虑当地电费、建设成本,不同中心的算力单价略有差异。
- 承诺用量折扣:客户承诺长期使用一定量算力,可获得阶梯价格优惠。
- 竞价模式:对于非实时性任务,可提交至“算力资源池”,以竞价方式使用空闲算力,成本显著降低。
- 设备资产与成本分摊:对于自购或租赁的GPU服务器等硬件设备,其折旧/租金、运维成本(电力、制冷、人工)被科学地分摊到每个“算力单元”中,作为定价的基础成本,确保财务模型的可持续性。
四、 成效与启示
通过上述体系,该智算中心集群实现了:
- 运营效率提升:故障平均修复时间(MTTR)降低30%,资源整体利用率提升至65%以上。
- 客户体验优化:客户可“一点接入,全网算力”,按需取用,账单透明。
- 商业闭环清晰:形成了从资源供给、监控调度、计量计费到财务回款的完整闭环。
结论
多地智算中心的运营运维绝非单个数据中心的简单复制。它要求构建一个技术驱动、流程统一、财务透明的整体系统。成功的核心在于通过集中化的智能平台实现“管控合一”,并通过精细化的结算模型将分散的物理设备转化为可灵活销售、收益明确的算力服务,从而真正释放规模化的算力网络价值。本案例为同类项目的规划与运营提供了可借鉴的实践框架。
如若转载,请注明出处:http://www.dtjwg.com/product/22.html
更新时间:2026-06-18 11:34:28